Improved Omnidirectional Small Moving Object Detection with an Enhanced YOLO Model
- Research
A new enhanced YOLO framework improves the detection accuracy of distant and small moving objects in omnidirectional videos
While omnidirectional cameras can provide a 360-degree field of view, they often struggle to detect small moving objects, as important visual details are lost due to distortion and low resolution, even when distortion reduction methods are applied. A new study addresses this problem by building an annotated training dataset and refining a You Only Look Once (YOLO)-based detection model through transfer learning. The method substantially outperformed standard YOLO models, especially for small and distant objects.
 Title:A newly trained YOLO model with improved small moving object detection can enhance road safety
Title:A newly trained YOLO model with improved small moving object detection can enhance road safety
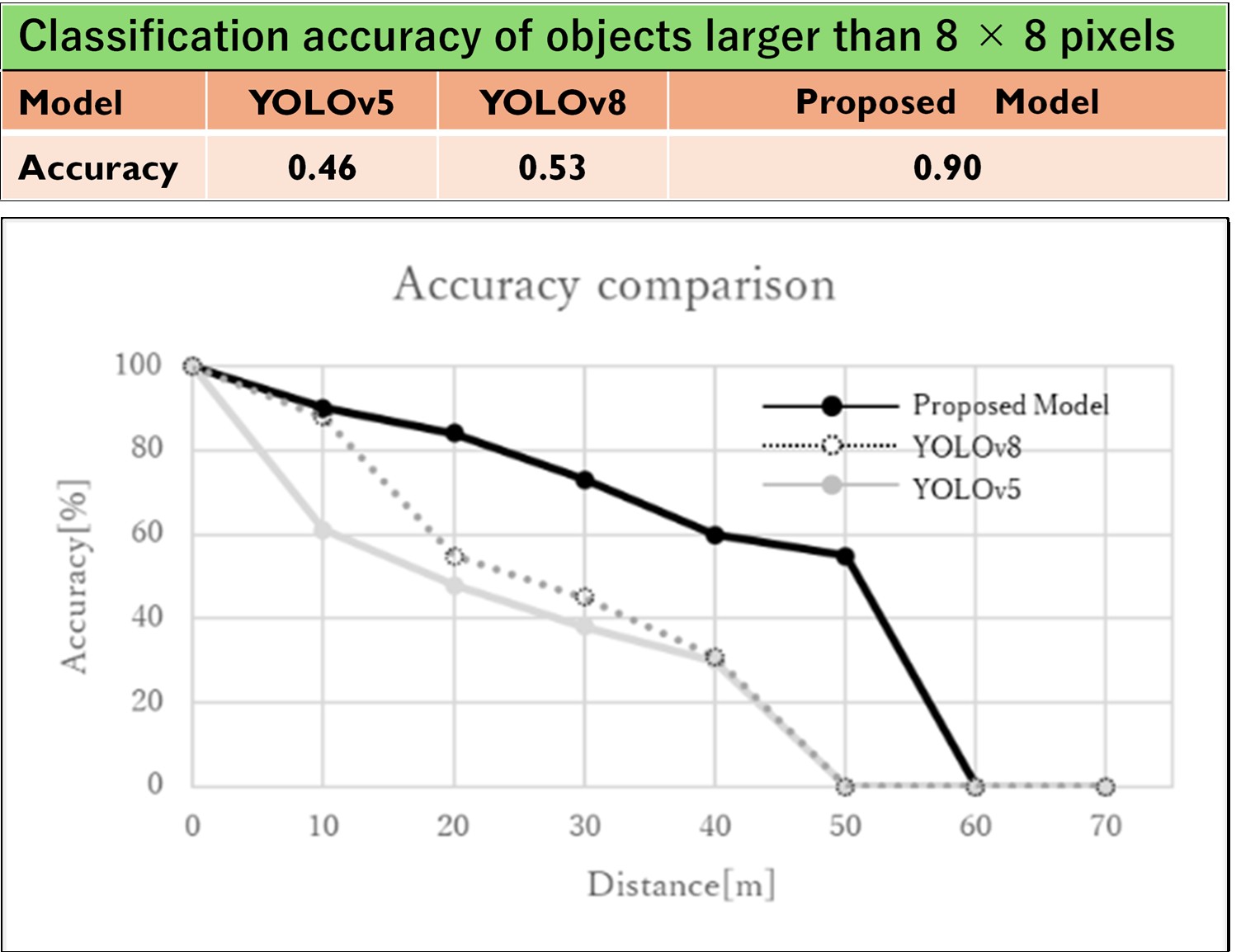
Caption:Researchers from Shibaura Institute of Technology, Japan, developed a newly trained You Only Look Once (YOLO) model using transfer learning that can detect small moving objects with improved accuracy compared to standard models. The proposed method maintains high accuracy even at 50 meters, whereas standard YOLO models showed a steep drop in accuracy beyond 40 meters. The graph in the figure shows the accuracy comparison with respect to distance.
Credit:Professor Chinthaka Premachandra from Shibaura Institute of Technology, Japan
Source Link:N/A
License Type: Original content
Usage restrictions: Credit must be given to the creator.
Omnidirectional cameras are widely popular as they capture a full 360-degree view. They are often utilized for surveillance, traffic analysis, and autonomous systems. But the same wide-angle vision also leads to a technical problem. Objects far from the camera often appear distorted and tiny, making it difficult for computer vision systems to accurately recognize them. The challenge is especially serious for moving objects such as pedestrians, bicycles, motorcycles, and cars in outdoor scenes like road intersections.
You Only Look Once (YOLO) is a popular, high-speed, and accurate real-time object detection algorithm. Although YOLO is known for speed and strong general performance, it struggles with small object detection/classification in omnidirectional videos, as it divides an image into grid cells. When several tiny objects fall within the same grid, some of their visual information can be lost. In omnidirectional footage, this weakness becomes even more pronounced because distant objects already suffer from low resolution.
To address this issue, a team of researchers led by Professor Chinthaka Premachandra from Shibaura Institute of Technology, Japan, designed an enhanced framework that combined a custom-built training dataset with transfer learning. “In many countries, including Japan, road intersections are extremely accident-prone areas due to the complex interactions of vehicles, pedestrians, and cyclists moving from multiple directions. Some of these road users may suddenly appear from blind spots at intersections, further increasing the likelihood of accidents. Our research was initiated to solve this particular issue,” mentions Dr. Premachandra, while talking about the motivation behind this study. The paper was published in Volume 7 of the journal IEEE Open Journal of Intelligent Transportation Systems on March 4, 2026.
For developing the model, a dataset of about 4,000 annotated images was created, covering four categories—humans, cars, bicycles, and motorcycles. Importantly, the annotations were not generic. Omnidirectional cameras exhibit a rapid decrease in resolution as the distance between the camera and the object increases, and the objects are often misidentified. To mitigate this issue, the team defined characteristic features for each moving object class to help the model learn what to look for under difficult conditions. For example, a human needed at least one arm or leg to be visible, a car needed two or more tires to be visible, and bicycles and motorcycles needed both front and rear wheels to be visible.
The research team also strengthened the dataset by cropping images and including objects viewed from multiple angles so that small and less frequent targets would be better represented. The dataset was used for training via transfer learning, a method that adapts the knowledge of an existing model to a new domain. Finally, the trained model was compared against conventional models for accuracy.
In direct comparisons, the proposed model reached an overall accuracy of 90%, while YOLOv5 achieved 46% and YOLOv8 achieved 53% for objects larger than 8 × 8 pixels. For small moving objects specifically, ranging from 8 × 8 to 32 × 32 pixels, the proposed model achieved an accuracy of 0.81, which is significantly higher compared to 0.39 for YOLOv5 and 0.42 for YOLOv8. The study also found that while standard YOLO models showed a steep drop in accuracy beyond 40 meters, the new model maintained useful performance up to 50 meters.
This research addresses a critical limitation in current perception systems by improving the detection of small and distant objects across a full 360° field of view. “This approach can be effectively applied to intelligent transportation systems, autonomous driving, and robotic navigation, where reliable omnidirectional perception is essential. Specifically, it is well-suited for intersection monitoring and safety assistance, where vehicles, pedestrians, and cyclists may approach from multiple directions simultaneously,” explains Dr. Premachandra, while talking about the application of this research.
Let us hope the research progresses quickly to develop models with enhanced detection accuracy for objects smaller than 8 × 8 pixels, which can further reduce the risks of accidents and improve road safety.
Reference
|
Title of original paper: |
E-YOLO to OMOD: An Enhanced YOLO Framework for Small Moving Object Detection in Omnidirectional Videos |
|
Journal: |
IEEE Open Journal of Intelligent Transportation Systems |
|
DOI: |
Authors
About Professor Chinthaka Premachandra from SIT, Japan
Dr. Chinthaka Premachandra is a Professor at the College of Engineering and Graduate School of Engineering and Science, Shibaura Institute of Technology, Japan. He is also currently the Director of the Image Processing and Robotics Laboratory. Prof. Premachandra received his Ph.D. degree from Nagoya University, Nagoya, Japan, in 2011. His research interests include AI, UAVs, image processing, audio processing, intelligent transport systems (ITS), and mobile robotics. He has published over 200 articles over the years, which have been cited more than 1,500 times. He is currently also serving as an Associate Editor for IEEE Robotics and Automation Letters and IEEE Sensors Journal.
Funding Information
Not applicable